- Дальнейшее чтение на SmashingMag:
- ASCII
- Попробуй сам
- Восьмой бит
- Попробуй сам
- Резюме Около 1990
- Юникод на помощь
- Юникод внутри браузера
- Попробуй сам
- UTF-8 на помощь
- Попробуй сам
- Резюме Около 2003
- Много проблем
- HTML-сущности
- Смущенные персонажи
- Акцентированные персонажи с большим количеством гласных
- Чередование акцентированных персонажей
- Черный бриллиант
- Бланки, вопросительные знаки и коробки
- Базы данных
- Попробуй сам
- Одно решение
- Существующие сайты
- Резюме
Эта история восходит к самым ранним дням компьютеров. У истории есть сюжет, ну вроде. У этого есть соревнование и интрига, так же как пересечение множества стран и языков. Есть конфликт и разрешение, и счастливый конец.
Но основное внимание уделяется персонажам - 110 116 из них. К концу истории они все найдут свое уникальное место в этом мире.
Эта статья будет более внимательно следить за некоторыми из этих персонажей при переходе от веб-сервера к браузеру и обратно. Попутно вы узнаете больше об истории символов, наборах символов, Unicode и UTF-8, а также о том, почему вопросительные знаки и нечетные символы с акцентом иногда появляются в базах данных и текстовых файлах.
Дальнейшее чтение на SmashingMag:
Предупреждение : эта статья содержит множество цифр, в том числе немного двоичных, к которым лучше всего подходить после утренней чашки кофе.
ASCII
Компьютеры имеют дело только с цифрами, а не с буквами, поэтому важно, чтобы все компьютеры согласовывали, какие цифры представляют какие буквы.
Допустим, мой компьютер использовал цифры 1 для A, 2 для B, 3 для C и т. Д., А ваш использовал 0 для A, 1 для B и т. Д. Если я отправил вам сообщение HELLO, то цифры 8, 5, 12, 12, 15 просвистел бы по проводам. Но для вас 8 означает I, поэтому вы получите и расшифруете его как IFMMP. Чтобы эффективно общаться, нам нужно договориться о стандартном способе кодирования символов.
С этой целью в 1960-х годах Американская ассоциация стандартов создала 7-битную кодировку под названием Американский стандартный код для обмена информацией ( ASCII ). В этом кодировании HELLO равен 72, 69, 76, 76, 79 и будет передаваться в цифровом виде как 1001000 1000101 1001100 1001100 1001111. Использование 7 битов дает 128 возможных значений от 0000000 до 1111111, поэтому ASCII имеет достаточно места для всех строчных и прописных букв Латинские буквы, а также каждая цифра, общие знаки препинания, пробелы, символы табуляции и другие управляющие символы. В 1968 году Президент США Линдон Джонсон сделал это официальным - все компьютеры должны использовать и понимать ASCII.
Попробуй сам
Есть много ASCII таблицы доступно, отображение или описание 128 символов. Или вы можете сделать свой собственный с небольшим количеством CSS, HTML и Javascript, большинство из которых состоит в том, чтобы он хорошо отображался:
<html> <body> <style type = "text / css"> p {float: left; отступы: 0 15px; поле: 0; размер шрифта: 80%;} </ style> <script type = "text / javascript"> для (var i = 0; i <128; i ++) document.writeln ((i% 32? ':' <p> ') + i +': '+ String.fromCharCode (i) +' <br> '); </ script> </ body> </ html>
Это покажет таблицу как это:
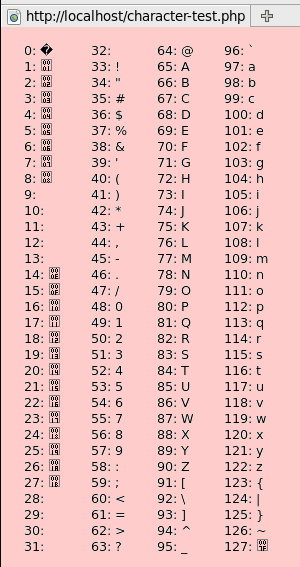
Сделай сам Javascript ASCII таблица, просмотренная в Firefox
Наиболее важным из них является функция Javascript String.fromCharCode. Он берет число и превращает его в персонажа. Фактически, следующие четыре строки HTML и Javascript дают одинаковый результат. Все они заставляют браузер отображать символы с номерами 72, 69, 76, 76 и 79:
HELLO HELLO <script> document.write ("HELLO"); </ script> <script> document.write (String.fromCharCode (72,69,76,76,79)); </ script>
Также обратите внимание на то, как Firefox отображает непечатаемые символы (например, backspace и escape) в первом столбце. Некоторые браузеры показывают пробелы или вопросительные знаки. Firefox сжимает четыре шестнадцатеричные цифры в небольшую коробку.
Восьмой бит
телетайпов и биржевые тикеры были очень счастливы, посылая 7 битов информации друг другу. Но новый запутался микропроцессоры из 1970-х годов предпочитали работать со степенями 2. Они могли обрабатывать 8 битов за раз и поэтому использовали 8 бит (или байт или октет) для хранения каждого символа, давая 256 возможных значений.
8-битный символ может хранить число до 255, но ASCII назначает только до 127. Другие значения от 128 до 255 являются запасными. Первоначально ПК IBM использовали запасные слоты для представления акцентированных букв, различных символов и форм и нескольких греческих букв. Например, число 200 - это нижний левый угол поля: ╚, а 224 - греческая буква альфа в нижнем регистре: α . Этот способ кодирования букв был позже назван кодовая страница 437 ,
Однако, в отличие от ASCII, символы 128-255 никогда не были стандартизированы, и различные страны начали использовать свободные слоты для своих собственных алфавитов. Не все согласились с тем, что 224 должен отображать α , даже греки. Это привело к созданию нескольких новых кодовые страницы , Например, на российских компьютерах IBM, использующих кодовую страницу 885, 224 представляет кириллицу Я. А в греческой кодовой странице 737 это строчные буквы омега: ω .
Даже тогда были разногласия. С 1980-х годов Microsoft Windows представила свои собственные кодовые страницы. В кодовой странице кириллицы Windows-1251, 224 представляет букву кириллицы а , а Я - 223.
В конце 1990-х была предпринята попытка стандартизации. Было создано 15 различных 8-битных наборов символов, чтобы охватить множество различных алфавитов, таких как кириллица, арабский, иврит, турецкий и тайский. Они называются ISO-8859-1 до ISO-8859-16 (номер 12 был заброшен). В кириллице ISO-8859-5, 224 представляет букву р , а Я на 207.
Поэтому, если русский друг отправит вам документ, вам действительно нужно знать, какую кодовую страницу он использует. Сам по себе документ - это просто последовательность цифр. Персонаж 224 может быть Я , а или р . При просмотре с использованием неправильной кодовой страницы она будет выглядеть как набор закодированных букв и символов.
(Ситуация не так плоха при просмотре веб-страниц - поскольку веб-браузеры обычно могут определять набор символов страницы на основе частотного анализа и других подобных методов. Но это ложное чувство безопасности - они могут и действительно ошибаются. )
Попробуй сам
Кодовые страницы также известны как наборы символов . Вы можете исследовать эти наборы символов самостоятельно, но на этот раз вы должны использовать PHP или аналогичный язык на стороне сервера (примерно потому, что символ должен быть на странице, прежде чем он попадет в браузер). Сохраните эти строки в файле PHP и загрузите их на свой сервер:
<html> <head> <meta charset = "ISO-8859-5"> </ head> <body> <style type = "text / css"> p {float: left; отступы: 0 15px; поле: 0; размер шрифта: 80%;} </ style> <? php для ($ i = 0; $ i <256; $ i ++) echo ($ i% 32? ':' <p> '). $ я ':'. chr ($ i). '<br>'; ?> </ body> </ html>
Это покажет таблицу как это:
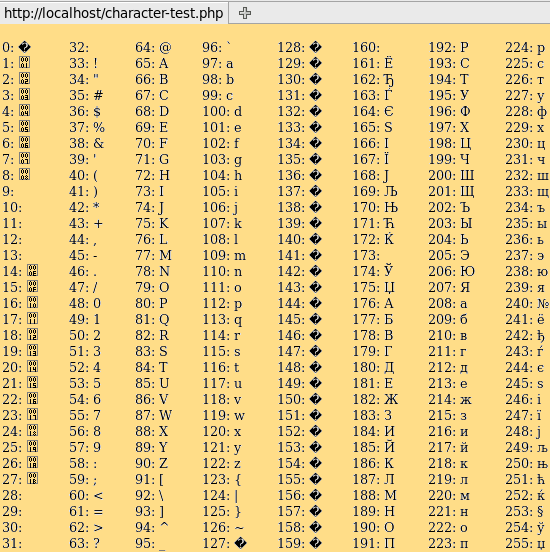
Набор символов кириллицы ISO-8859-5 в Firefox
Функция PHP chr делает то же самое, что и Javascript String.fromCharCode. Например, chr (224) встраивает число 224 в веб-страницу перед отправкой в браузер. Как мы видели выше, 224 может означать много разных вещей. Итак, браузер должен знать, какой набор символов использовать для отображения 224. Для этого предназначена первая строка выше. Он говорит браузеру использовать кириллицу ISO-8858-5:
<meta charset = "ISO-8859-5">
Если вы исключите строку кодировки, она будет отображаться с использованием браузера по умолчанию. В странах с алфавитами, основанными на латинице (например, в Великобритании и США), это, вероятно, ISO-8859-1, и в этом случае 224 представляет собой знак с серьезным акцентом: а . Попробуйте изменить эту строку на ISO-8859-7 или Windows-1251 и обновите страницу. Вы также можете переопределить набор символов в браузере. В Firefox перейдите в «Вид»> «Кодировка символов». Переключитесь между несколькими, чтобы увидеть, какой эффект это имеет. Если вы попытаетесь отобразить более 256 символов, последовательность повторится.
Резюме Около 1990
Это примерно в 1990 году. Документы можно писать, сохранять и обмениваться на многих языках, но вам необходимо знать, какой набор символов они используют . Также нет простого способа использовать два или более неанглийских алфавита в одном документе, и алфавиты с более чем 256 символами, такими как китайский и японский, должны использовать совершенно разные системы.
Наконец-то интернет идет! Интернационализация и глобализация вот-вот сделают эту проблему гораздо более серьезной. Требуется новый стандарт.
Юникод на помощь
Начиная с конца 1980-х годов был предложен новый стандарт, который назначал бы уникальный номер (официально известный как кодовая точка) каждой букве на каждом языке, который имел бы более 256 слотов. Он назывался Unicode , Это сейчас в версии 6.1 и состоит из более чем 110 000 кодов. Если у вас есть несколько свободных часов, вы можете смотреть их все в прошлом ,
Первые 128 кодовых точек Unicode совпадают с ASCII. Диапазон 128-255 содержит символы валюты и другие общие знаки и символы ударения (или символы с диакритические знаки ), и большая его часть заимствована ISO-8859-1. После 256 есть еще много символов с акцентом. После 880 года он попадает на греческие буквы, затем на кириллицу, иврит, арабский, индийский и тайский. Китайский, японский и корейский начинаются с 11904 года, а многие другие между ними.
Это здорово - не более двусмысленности - каждая буква представлена своим уникальным номером. Кириллица Я всегда равна 1071, а греческая буква α всегда равна 945. 224 всегда равна а , а Н все равно 72. Обратите внимание, что эти кодовые точки Unicode официально записаны в шестнадцатеричном формате с предшествующим U +. Таким образом, кодовая точка Unicode H обычно записывается как U + 0048, а не 72 (для преобразования из шестнадцатеричного в десятичное: 4 * 16 + 8 = 72).
Основная проблема в том, что их более 256. Символы больше не будут вписываться в 8 бит. Однако Unicode не является набором символов или кодовой страницей . Официально это не проблема Консорциума Unicode. Они просто пришли с идеей и оставили кого-то другого, чтобы разобраться в реализации. Это будет обсуждаться в следующих двух разделах.
Юникод внутри браузера
Unicode не вписывается в 8 битов, даже в 16. Хотя используются только 110 116 кодовых точек, он имеет возможность определять до 1114 112 из них, что потребует 21 бит.
Тем не менее, компьютеры продвинулись с 1970-х годов. 8-битный микропроцессор немного устарел. Новые компьютеры теперь имеют 64-битные процессоры, так почему же мы не можем выйти за пределы 8-битного символа и перейти к 32-битному или 64-битному символу?
Первый ответ: мы можем!
Много программного обеспечения написано на C или C ++, который поддерживает «широкий символ». Это 32-битный символ с именем wchar_t. Это расширение 8-битного типа символов Си. Внутренне современные веб-браузеры используют эти широкие символы (или что-то подобное) и теоретически вполне могут справиться с более чем 4 миллиардами различных символов. Это достаточно для Unicode. Так что, во- первых, современные веб-браузеры используют Unicode .
Попробуй сам
Приведенный ниже код Javascript аналогичен приведенному выше коду ASCII, за исключением того, что он поднимается до гораздо большего числа. Для каждого номера он говорит браузеру отображать соответствующую кодовую точку Unicode:
<html> <body> <style type = "text / css"> p {float: left; отступы: 0 15px; поле: 0; размер шрифта: 80%;} </ style> <script type = "text / javascript"> для (var i = 0; i <2096; i ++) document.writeln ((i% 256? ':' <p> ') + i +': '+ String.fromCharCode (i) +' <br> '); </ script> </ body> </ html>
Он выведет таблицу примерно так:
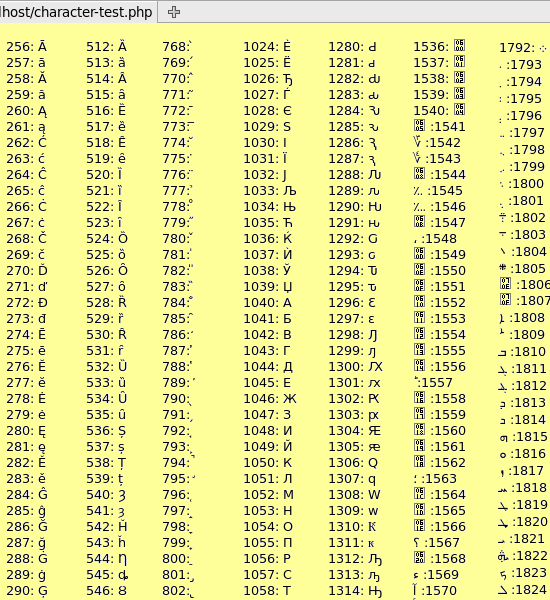
Выбор кодовых точек Unicode, просматриваемых в Firefox
Снимок экрана выше показывает только подмножество первых нескольких тысяч кодовых точек, выведенных Javascript. Выбор включает в себя некоторые кириллические и арабские символы, отображаемые справа налево.
Важным моментом здесь является то, что Javascript полностью запускается в веб-браузере, где 32-битные символы вполне приемлемы. Функция Javascript String.fromCharCode (1071) выводит кодовую точку Unicode 1071, которая является буквой Я.
Аналогично, если вы поместите HTML-сущность Я на HTML-страницу, современный веб-браузер отобразит Я. Числовые сущности HTML также относятся к Unicode.
С другой стороны, PHP-функция chr (1071) выдаст косую черту /, потому что функция chr работает только с 8-битными числами до 256 и повторяется после этого, а 1071% 256 = 47, что было / с 1960-й года.
UTF-8 на помощь
Так что, если браузеры могут работать с Unicode в 32-битных символах, в чем проблема? Проблема в отправке и получении, а также в чтении и написании символов.
Проблема остается, потому что:
- Множество существующих программ и протоколов отправляют / получают и читают / пишут 8-битные символы
- Использование 32 бит для отправки / хранения английского текста увеличило бы в четыре раза количество необходимой полосы пропускания / места
Хотя браузеры могут работать с Unicode внутренне, вам все равно придется передавать данные с веб-сервера в веб-браузер и обратно, и вам необходимо сохранить их в файле или базе данных где-нибудь. Таким образом, вам все еще нужен способ, чтобы 110 000 кодовых точек Unicode вписались в 8 бит.
Было несколько попыток решить эту проблему, таких как UCS2 и UTF-16. Но в последние годы победителем стал UTF-8, который расшифровывается как 8-битный формат универсального набора символов.
UTF-8 умный. Это работает немного как клавиша Shift на клавиатуре. Обычно, когда вы нажимаете клавишу H на клавиатуре, на экране появляется строчная буква «h». Но если вы сначала нажмете Shift, появится заглавная буква H.
UTF-8 рассматривает числа 0-127 как ASCII, 192-247 как клавиши Shift и 128-192 как клавишу для сдвига. Например, символы 208 и 209 сдвигают вас в диапазон кириллицы. 208 затем 175 символ 1071, кириллица Я. точный расчет is (208% 32) * 64 + (175% 64) = 1071. Символы 224-239 подобны двойной смене. 226, затем 190, а затем 128 символ 12160: ⾀. 240 и более - это тройной сдвиг.
UTF-8, следовательно, является многобайтовым кодированием переменной ширины. Многобайтовый, потому что один символ, такой как Я, требует более одного байта для его указания. Переменная ширина, потому что некоторые символы, такие как H, занимают всего 1 байт, а некоторые - до 4.
Лучше всего это обратно совместимо с ASCII. В отличие от некоторых других предлагаемых решений, любой документ, написанный только в ASCII, использующий только символы 0-127, также является совершенно допустимым UTF-8, что экономит полосу пропускания и хлопоты.
Попробуй сам
Это другой эксперимент. PHP встраивает 6 упомянутых выше чисел в HTML-страницу: 72, 208, 175, 226, 190, 128. Браузер интерпретирует эти числа как UTF-8 и внутренне преобразует их в кодовые точки Unicode. Затем Javascript выводит значения Unicode. Попробуйте изменить набор символов с UTF-8 на ISO-8859-1 и посмотрите, что произойдет:
<html> <head> <meta charset = "UTF-8"> </ head> <body> <p> Символы, встроенные в страницу: <br> <span id = "chars"> <? php echo chr (72 ) .chr (208) .chr (175) .chr (226) .chr (190) .chr (128); ?> </ span> <p> Символьные значения в соответствии с Javascript: <br> <script type = "text / javascript"> function ShowCharacters (s) {var r = '; for (var i = 0; i <s.length; i ++) r + = s.charCodeAt (i) + ':' + s.substr (i, 1) + '<br>'; return r;} document.writeln (ShowCharacters (document.getElementById ('chars'). innerHTML)); </ script> </ body> </ html>
Если вы спешите, это будет выглядеть так:
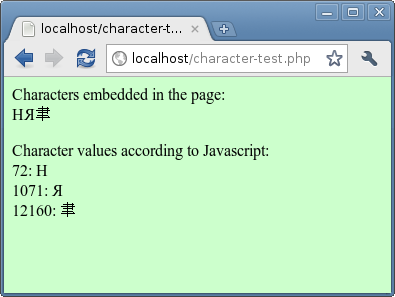
Последовательность чисел, показанная выше, с использованием набора символов UTF-8
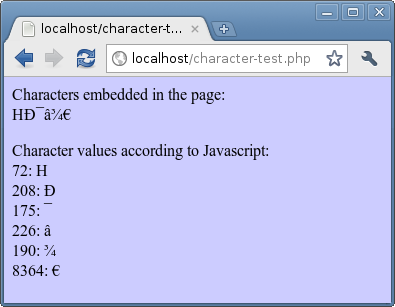
Та же последовательность цифр показана с использованием набора символов ISO-8859-1
Если вы отображаете страницу, используя набор символов UTF-8, вы увидите только 3 символа: HЯ ⾀. Если вы отобразите его с помощью набора символов ISO-8859-1, вы увидите шесть отдельных символов: HЯ⾠€. Вот что происходит:
- На вашем веб-сервере PHP встраивает числа 72, 208, 175, 226, 190 и 128 в веб-страницу
- Веб-страница просвистывает через Интернет с веб-сервера на ваш веб-браузер
- Браузер получает эти числа и интерпретирует их в соответствии с набором символов
- Браузер внутренне представляет символы, используя их значения Unicode
- Javascript выводит соответствующие значения Unicode
Обратите внимание, что при рассмотрении как ISO-8859-1 первые 5 чисел совпадают (72, 208, 175, 226, 190) с их кодовыми точками Unicode. Это связано с тем, что Unicode сильно заимствовал из ISO-8859-1 в этом диапазоне. Последнее число, однако, символ евро €, отличается. Он находится в позиции 128 в ISO-8859-1 и имеет значение Unicode 8364.
Резюме Около 2003
UTF-8 становится самым популярным международным набором символов в Интернете, заменяя старые однобайтовые наборы символов, такие как ISO-8859-5. Когда вы просматриваете или отправляете документ не на английском языке, вам все равно нужно знать, какой набор символов он использует. Для обеспечения максимальной совместимости администраторы веб-сайтов должны убедиться, что все их веб-страницы используют наборы символов UTF-8.
Возможно, это выглядит знакомо - иногда оно будет появляться, если вы попытаетесь просмотреть русские документы UTF-8. В следующем разделе описывается, как наборы символов запутываются и в итоге неправильно хранят данные в базе данных.
Много проблем
Пока все говорят на UTF-8, все должно работать без сбоев. Если это не так, то персонажи могут стать искалеченными. Чтобы объяснить путь, представьте типичное взаимодействие веб-сайта, например, когда пользователь комментирует сообщение в блоге:
- Веб-страница отображает форму комментария
- Пользователь вводит комментарий и отправляет.
- Комментарий отправляется обратно на сервер и сохраняется в базе данных.
- Позднее комментарий извлекается из базы данных и отображается на веб-странице.
Этот простой процесс может пойти не так во многих отношениях и привести к следующим типам проблем:
HTML-сущности
Представьте на мгновение, что вы ничего не знаете о наборах символов - сотрите последние 30 минут из своей памяти. Форма в вашем блоге, вероятно, будет отображаться с использованием набора символов ISO-8859-1. Этот набор символов не знает русского, тайского или китайского, и немного греческого. Если вы попытаетесь скопировать и вставить любой элемент в форму и нажать «Отправить», современный браузер попытается преобразовать его в числовые объекты HTML, такие как «Я» для « Я» .
Это то, что будет сохранено в вашей базе данных, и это то, что будет выводиться при отображении комментария - это означает, что он будет хорошо отображаться на веб-странице, но вызывает проблемы, когда вы пытаетесь вывести его в PDF или по электронной почте или запустить текст ищет его в базе данных.
Смущенные персонажи
Как насчет того, если вы используете русский веб-сайт, и вы не указали набор символов на своей веб-странице? Представьте себе русского пользователя, чей набор символов по умолчанию - ISO-8859-5. Чтобы сказать «привет», они могут напечатать Привет. Когда пользователь нажимает кнопку «Отправить», символы кодируются в соответствии с набором символов на странице отправки . В этом случае Привет кодируется как числа 191, 224, 216, 210, 213 и 226. Эти числа будут отправляться через Интернет на сервер и таким образом сохраняться в базе данных.
Если кто-то позже просмотрит этот комментарий, используя ISO-8859-5, он увидит правильный текст. Но если они просматривают, используя другой русский набор символов, такой как Windows-1251, они увидят «ШТХв». Это все еще русский, но не имеет смысла.
Акцентированные персонажи с большим количеством гласных
Если кто-то просматривает тот же комментарий, используя ISO-8859-1, он увидит При àØÒÕâ вместо Привет. Более длинная фраза типа «Я тоже рада Вас видеть» («приятно видеть вас» формально для женщины), представленная как ISO-8859-5, будет отображаться в ISO-8859-1 как as âÞÖÕ àÐÔÐ. Это выглядит так, потому что диапазон ISO-8859-1 128-255 содержит много гласных с ударениями.
Поэтому, если вы видите этот тип шаблона, это, вероятно, потому, что текст был введен в однобайтовый набор символов (один из ISO-8859 или Windows) и отображается как ISO-8859-1. Чтобы исправить текст, вам нужно выяснить, в каком наборе символов он был введен, и вместо этого повторно отправить его как UTF-8.
Чередование акцентированных персонажей
Что если пользователь отправил комментарий в UTF-8? В этом случае символы кириллицы, составляющие слово Привет, будут отправляться по 2 цифры: 208–159, 209–128, 208–184, 208–178, 208–181 и 209–130. Если бы вы видели это в ISO-8859-1, это выглядело бы как: ÐŸÑ € Ð¸Ð²ÐµÑ ‚.
Обратите внимание, что любой другой символ является Ð или Ñ. Это символы с номерами 208 и 209, и они говорят UTF-8 переключиться на диапазон кириллицы. Поэтому, если вы видите много символов Ð и Ñ, вы можете предположить, что вы смотрите на русский текст, введенный в UTF-8, который рассматривается как ISO-8859-1. Точно так же греческий будет иметь много of и Ï, 206 и 207. И у иврита чередуется ×, число 215.
Очень распространенная проблема в Великобритании - символ валюты £, конвертируемый в £. Это точно та же проблема, что и выше, с добавленным совпадением, чтобы добавить путаницу. Символ £ имеет значение Unicode и ISO-8859-1 163. Напомним, что в UTF-8 любой символ свыше 127 представлен последовательностью из двух или более чисел. В этом случае последовательность UTF-8 равна 194-163. Математически это потому, что (194% 32) * 64 + ( 163 % 64) = 163 .
Визуально это означает, что если вы просматриваете последовательность UTF-8 с использованием ISO-8859-1, она, кажется, получает символ Â, который в ISO-8859-1 является символом 194. То же самое происходит для всех кодовых точек Unicode 161-191, включая © и ® и ¥.
Так что, если ваши £ или © внезапно наследуют, это потому, что они были введены как UTF-8.
Черный бриллиант
Как насчет наоборот? Если вы введете Привет как ISO-8859-5, он будет сохранен как числа, показанные выше: 191, 224 и т. Д. Если вы затем попытаетесь просмотреть это как UTF-8, вы можете увидеть множество вопросительных знаков внутри черных бриллиантов : . Браузер отображает их, когда не может понять числа, которые он читает.
UTF-8 самосинхронизируется. В отличие от других многобайтовых кодировок символов, вы всегда знаете, где находитесь с UTF-8. Если вы видите число 192-247, вы знаете, что находитесь в начале многобайтовой последовательности. Если вы видите 128-191, вы знаете, что вы в середине. Нет опасности пропустить первый номер и искажать остальную часть текста.
Это означает, что в UTF-8 последовательность 191, за которой следует 224, никогда не будет происходить естественным образом, поэтому браузер не знает, что с ним делать, и вместо этого отображает .
Это также может вызвать проблемы с £ и ©. £ 50 в ISO-8859-1 - это числа 163, 53 и 48. 53 и 48 не вызывают проблем, но в UTF-8 163 не может возникнуть само по себе, поэтому это будет равно as50. Точно так же, если вы видите ,2012, это, вероятно, потому что © 2012 был введен как ISO-8859-1, но отображается как UTF-8.
Бланки, вопросительные знаки и коробки
Даже если они полностью соответствуют UTF-8 и Unicode, браузер все еще может не знать, как отображать символы. Первые несколько символов ASCII 1-31 в основном являются управляющими последовательностями для телепринтеров (например, Acknowledge и Stop). Если вы попытаетесь отобразить их, браузер может показать? или пробел или ящик с крошечными цифрами внутри.
Кроме того, Unicode определяет более 110 000 символов. Ваш браузер может не иметь правильный шрифт для отображения всех из них. Некоторые из более неясных персонажей также могут отображаться как? или пустой или маленький ящик. В старых браузерах даже довольно распространенные неанглийские символы могут отображаться в виде блоков.
Старые браузеры могут также вести себя по-разному для некоторых из вышеперечисленных проблем, показывая? и пустые коробки чаще.
Базы данных
Приведенное выше обсуждение позволило избежать среднего этапа процесса - сохранения данных в базе данных. Базы данных, такие как MySQL, также могут указывать набор символов для базы данных, таблицы или столбца. Но менее важно, что набор символов веб-страниц.
При сохранении и получении данных MySQL работает только с числами. Если вы скажете, чтобы сохранить номер 163, он будет. Если вы дадите ему 208⁄159, он сохранит эти два числа. И когда вы получите данные, вы получите те же два числа обратно.
Набор символов становится более важным, когда вы используете функции базы данных для сравнения, преобразования и измерения данных. Например, ДЛИНА поля может зависеть от его набора символов, как и сравнения строк с использованием LIKE и =. Метод, используемый для сравнения строк, называется сличение ,
Наборы символов и сопоставления в MySQL - предмет углубленного изучения. Это не просто случай изменения набора символов таблицы на UTF-8. Существуют и другие команды SQL, которые необходимо учитывать, чтобы данные входили и выходили в правильном формате.
Попробуй сам
Следующий код PHP и Javascript позволяет экспериментировать со всеми этими проблемами. Вы можете указать, какой набор символов используется для ввода и вывода текста, и вы можете видеть, что браузер думает об этом тоже.
<? php $ charset = $ _POST ['charset']; if (! $ charset) $ charset = 'ISO-8859-1'; $ string = $ _POST ['string']; if ($ string) {echo '<p> Это то, что PHP думает, что вы ввели: <br>'; for ($ i = 0; $ i <strlen ($ string); $ i ++) {$ c = substr ($ string, $ i, 1); echo ord ($ c). ':'. $ c. ' <br/> ';}}?> <html> <head> <meta charset = "<? = $ charset?>"> </ head> <body> <form method = "post"> <input name = " lastcharset "type =" hidden "value =" <? php echo $ charset?> "/> Форма была отправлена как: <? php echo $ _POST ['lastcharset']?> <br/> Текст отображается как: <? php echo $ charset?> <br/> Текст будет представлен как: <? php echo $ charset?> <br/> Скопируйте и вставьте или введите здесь: <input name = "string" type = "text" size = " 20 "value =" <? Php echo $ string?> "/> <br/> Следующая страница будет отображаться как: <select name =" charset "> <option> ISO-8859-1 <option> ISO-8859-5 <option> Windows-1251 <option> ISO-8859-7 <option> UTF-8 </ select> <br/> <input type = "submit" value = "Submit" onclick = "ShowCharacters (this.form.string .value); return 1; "/> </ form> <script type =" text / javascript "> function ShowCharacters (s) {var r = 'Вы ввели:'; for (var i = 0; i <s.length; i ++) r + = 'n' + s.charCodeAt (i) + ':' + s.substr (i, 1); оповещение (r); } </ script> </ body> </ html>
Это пример кода в действии. Числа вверху - это числовые значения каждого из символов и их представление (при просмотре по отдельности) в текущем наборе символов:
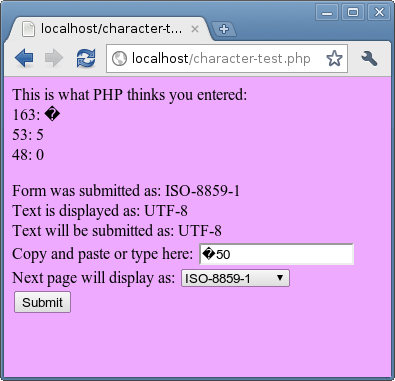
Пример ввода и вывода в разных наборах символов. Это показывает знак £, превращающийся в £ в Google Chrome.
На странице выше показаны предыдущие, текущие и будущие наборы символов. Вы можете использовать этот код, чтобы быстро увидеть, как текст может быть искажен. Например, если вы снова нажали «Отправить» выше, имеет кодовую точку Unicode 65533, которая равна 239/191/189 в UTF-8 и будет отображаться как ½50 в ISO-8859-1. Так что если вы когда-нибудь получите символы £, превращающиеся в ½, это, вероятно, тот путь, по которому они пошли.
Обратите внимание, что поле выбора внизу будет меняться на ISO-8859-1 каждый раз.
Одно решение
Все вышеперечисленные проблемы кодирования вызваны тем, что текст передается в одном наборе символов и просматривается в другом. Решение состоит в том, чтобы убедиться, что каждая страница на вашем сайте использует UTF-8 . Вы можете сделать это с помощью одной из этих строк сразу после тега <head>:
<meta charset = "UTF-8"> <meta http-equ = "Content-type" content = "text / html; charset = UTF-8">
Это должно быть одной из первых вещей на вашей веб-странице, так как это заставит браузер снова взглянуть на страницу в совершенно новом свете. Для скорости и эффективности, он должен сделать это как можно скорее.
Вы также можете указать UTF-8 в своих таблицах MySQL, хотя, чтобы полностью использовать эту функцию, вам нужно глубже вникнуть.
Обратите внимание, что пользователи по-прежнему могут переопределять набор символов в своих браузерах. Это редко, но означает, что это решение не гарантированно работает. Для дополнительной безопасности вы можете выполнить внутреннюю проверку, чтобы убедиться, что данные поступают в правильном формате.
Существующие сайты
Если ваш веб-сайт уже собирал текст на разных языках, вам также необходимо преобразовать существующие данные в UTF-8. Если его не так много, вы можете использовать страницу PHP, подобную приведенной выше, чтобы выяснить исходный набор символов, и использовать браузер для преобразования данных в UTF-8.
Если у вас много данных в различных наборах символов, вам нужно сначала определить набор символов, а затем преобразовать его. В PHP вы можете использовать mb_detect_encoding обнаружить и Iconv преобразовать. Читая комментарии для mb_detect_encoding, это выглядит довольно суетливой функцией, поэтому обязательно поэкспериментируйте, чтобы убедиться, что вы используете ее правильно и получаете правильные результаты.
Потенциально вводящая в заблуждение функция utf8_decode , Превращает UTF-8 в ISO-8859-1. Любые символы, отсутствующие в ISO-8859-1 (например, кириллица, греческий, тайский и т. Д.), Превращаются в знаки вопроса. Это вводит в заблуждение, потому что вы могли ожидать от него большего, но оно делает все возможное.
Резюме
Эта статья в значительной степени опиралась на цифры и постаралась не оставить камня на камне. Надеемся, что он обеспечил исчерпывающее понимание наборов символов, Unicode, UTF-8 и различных проблем, которые могут возникнуть. Мораль этой истории:
- Вам нужно знать набор символов, чтобы понять нелатинский текст
- Внутренне браузеры используют Unicode для представления символов
- Убедитесь, что на всех ваших веб-страницах указан набор символов UTF-8
Для немного другого подхода к этому вопросу, эта статья 2003 набор символов отлично. Спасибо за участие в этом эпическом путешествии.
Похожие
Chromecast - потоковое видео с ПК на телевизор никогда не было проще - Spider's WebChromecast, новейшую идею для объединения онлайн-видео и телевидения от Google, я хотел купить в сентябре в США, но из-за чрезвычайно низкой цены (35 долларов) оборудование было непобедимым в торговых точках. Мне удалось получить его только тогда, когда Amazon решил отправить его в Польшу. Он попал ко мне сегодня. Что такое Chromecast? Давайте вернемся к моему на мгновение Как установить Icinga и Icinga Web в Ubuntu 16.04
... помощью apt-get и запустим несколько экранов конфигурации, чтобы настроить серверную часть базы данных Icinga. Сначала загрузите ключ подписи пакета разработчиков Icinga и добавьте его в систему apt: curl -sSL https://packages.icinga.com/icinga.key | sudo apt-key add - Этот ключ будет использоваться для автоматической проверки целостности любого программного обеспечения, которое мы загружаем из репозитория Icinga. Теперь нам нужно добавить адрес Как подключить вентилятор в ванной: схема, видео, фото - Сам Электрик
... ная по определению храм чистоты и свежести"> Ванная по определению храм чистоты и свежести. Но это не всегда так, если в ней плохая вентиляция или вообще отсутствует. Тогда из храма чистоты комната превращается в рассадник плесени, грибов и насекомых, которые комфортно себя чувствуют во влажной атмосфере и сырости, а это несет в себе потенциальную угрозу жителям квартиры. В этой статье мы расскажем, как подключить вентилятор в ванной комнате своими руками, предоставив возможные схемы подключения, Как управлять данными диагностики и использования на iPhone и iPad
Чтобы улучшить качество и производительность своих устройств iOS, Apple регулярно собирает диагностическую информацию и информацию об использовании с iPhone и iPad своих клиентов. Диагностические Топ 10 ошибок в веб-дизайне
... самых больших ошибок в веб-дизайне. Смотрите ссылки на все эти списки внизу этой статьи. В этой статье представлены основные моменты: самые худшие ошибки веб-дизайна. (Обновлено 2011 г.) 1. Плохой поиск Чрезмерно буквальные поисковые системы снижают удобство использования, Лучшие провайдеры хостинга WordPress (2019)
У провайдеров хостинга WordPress часто есть свои собственные сервисы, которые поддерживают их предложения. Некоторые из них являются уникальными, например, расширенные службы кэширования SiteGround. Вместо того, чтобы пытаться обсуждать преимущества одного над другим, давайте рассмотрим некоторые ключевые функции нескольких ведущих провайдеров хостинга управляемых и неуправляемых WordPress. Кстати, если вам интересно, ПОЧЕМУ вам нужен хост, который предлагает пакет хостинга для Asus Zenfone 3 Deluxe - Тест и обзоры
... помощью смартфона можно просматривать веб-страницы, делать текстовые записи, снимать видео и фотографии или хранить все свои файлы, такие как музыка, фотографии или видео. На рынке представлено много брендов смартфонов. Мобильный телефон ASUS Zenfone 3 Deluxe - это смартфон, который позволит вам проявить креативность. Благодаря большому экрану ваш опыт работы в Интернете никогда не будет прежним. Это устройство имеет множество функций, которые позволят вам полностью насладиться Yoga Sun Salutation - Инструкция для начинающих по йоге + PDF для печати
... намическая последовательность упражнений, которую многим начинающим йогам трудно найти в начале. Сочетание дыхания и движения, а также многочисленные переходы от одного упражнения йоги к другому являются настоящей проблемой. Часто практикующие йогу приветствуют солнце очень быстро, новички в йоге не отстают и ошибки закрадываются. Эта статья блога хотела бы дать вам всесторонний обзор Приветствия Йоги Солнца и имеет следующие приоритеты: Я надеюсь, вам понравится читать. I% 32?
I% 32?
Lt;br>'; ?
Новые компьютеры теперь имеют 64-битные процессоры, так почему же мы не можем выйти за пределы 8-битного символа и перейти к 32-битному или 64-битному символу?
I% 256?
Chr (128); ?
Если вы попытаетесь отобразить их, браузер может показать?
Некоторые из более неясных персонажей также могут отображаться как?
Старые браузеры могут также вести себя по-разному для некоторых из вышеперечисленных проблем, показывая?
Lt;?




Добавить комментарий!